
Stephen Medium
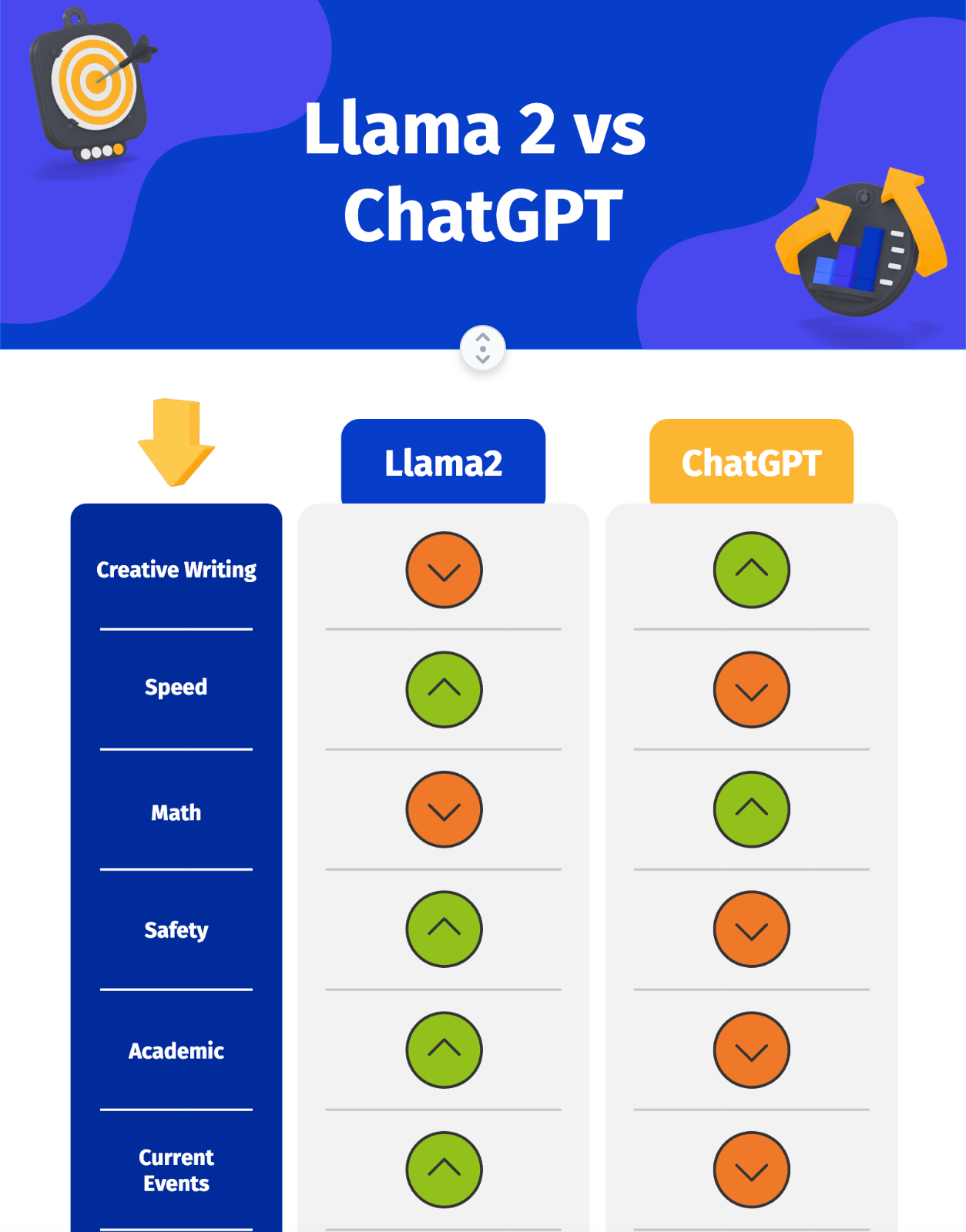
A bigger size of the model isnt always an advantage Sometimes its precisely the opposite and thats the case here. Web Apart from giveaways like this seems to me the main difference is actually not in the model itself but in the generation parameters temperature etc Here Llama is much more wordy and. Web When Llama 2 is not as good as GPT-35 and GPT-4 Llama 2 is a smaller model than GPT-35 and GPT-4 This means that it may not be able to handle tasks that require a. Web Llama 2 language model offer more up-to-date data than OpenAIs GPT-35 GPT-35 is more accessible than Llama 2 Llama 2s performance is higher than ChatGPT. Web According to Similarweb ChatGPT has received more traffic than Llama2 in the past month with about 25 million daily visits compared to about 19 million daily visits..
Medium balanced quality - prefer using Q4_K_M. Description This repo contains GGUF format model files for Metas Llama 2 7B About GGUF GGUF is a new format introduced by the llamacpp team on August 21st 2023. Initial GGUF model commit models made with llamacpp commit bd33e5a 75c72f2 6 months ago. Lets get our hands dirty and download the the Llama 2 7B Chat GGUF model After opening the page download the llama-27b-chatQ2_Kgguf file which is the most. GGUF is a new format introduced by the llamacpp team on August 21st 2023 It is a replacement for GGML which is no longer supported by llamacpp..
Stephen Medium
Result How to Fine-Tune Llama 2 In this part we will learn about all the steps required to fine-tune the Llama 2 model with 7 billion parameters. Contains examples script for finetuning and inference of the Llama 2 model as well as how to use them safely. Result The following tutorial will take you through the steps required to fine-tune Llama 2 with an example dataset using the Supervised Fine-Tuning SFT approach. Result In this guide well show you how to fine-tune a simple Llama-2 classifier that predicts if a texts sentiment is positive neutral or negative. Result In this notebook and tutorial we will fine-tune Metas Llama 2 7B Watch the accompanying video walk-through but for Mistral here If youd like to see that..
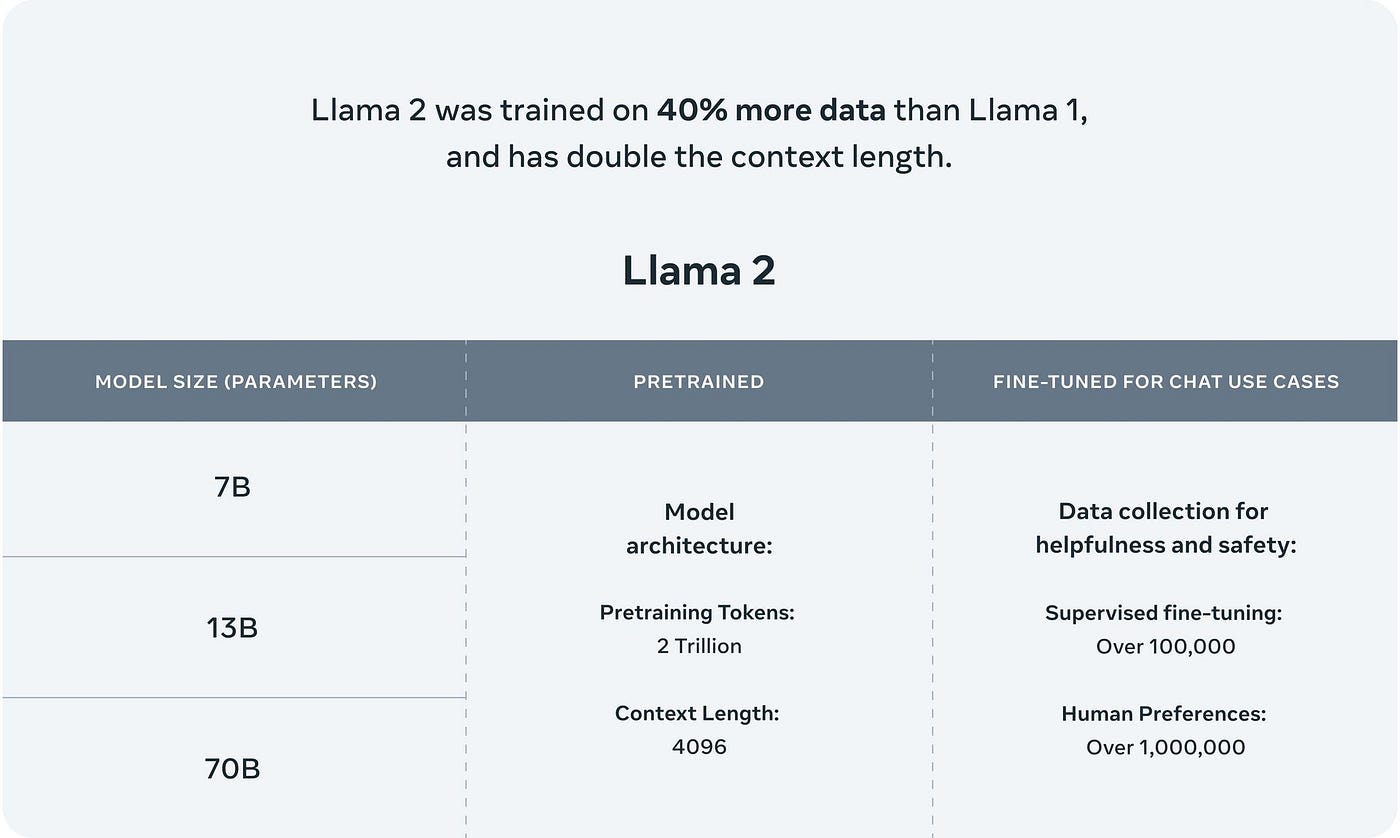
WEB LLaMA Llama-2 7B RTX 3060 GTX 1660 2060 AMD 5700 XT RTX 3050 AMD 6900 XT RTX 2060 12GB 3060 12GB 3080 A2000. WEB A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. WEB Some differences between the two models include Llama 1 released 7 13 33 and 65 billion parameters while Llama 2 has7 13 and 70 billion parameters Llama 2 was trained on 40 more. WEB Get started developing applications for WindowsPC with the official ONNX Llama 2 repo here and ONNX runtime here Note that to use the ONNX Llama 2 repo you will need to submit a request. WEB The Llama 2 family includes the following model sizes The Llama 2 LLMs are also based on Googles Transformer architecture but have some..


Comments